- 浏览: 59699 次
- 性别:

- 来自: 北京
-

最新评论
-
scu_cxh:
您好,我在学习hadoop方面的东西,想做一个对task监控的 ...
JobClient应用概述 -
bennie19870116:
看不到图呢...
Eclipse下配置使用Hadoop插件
最近的事确实很多,但大部分精力都放在了项目的设计方面,最近几天才完成了一些初步的编码的工作。在这个阶段,我发现,需要对数据的录入和Job执行的管理做细致的规划,否则在后期的扩展性上将有很大的局限。我设计的框架大体如下:
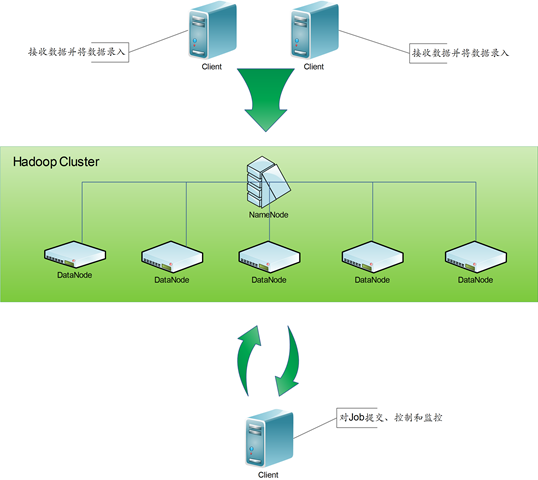
在这个结构里面,可以明显的看到我采用了2种Client,一个是数据录入层,一个是Job管理层。这里我说明一下为什么需要这2种Client。
1、数据录入主要接收数据,数据有多种形式传输,有流模式也有文件模式,为了不影响TaskTracker的性能,我采用Client单独的录入数据。
2、对于Job管理,因为Job任务有先后的顺序管理,而且对于失败的Job需要做重新的尝试,同时还要做到对Job的监控以及执行Job的增删。所以我单独采用一个Client对Job进行管理。实现Job执行的流程控制、状态反馈处理以及Job的热拔插。后面会详细说明。
到这里,可以看到,集群的应用我分成了3个部分。数据录入端、集群以及Job管理端。接下来我说下数据录入和Job管理的内容。
一、数据录入端
在这个部分主要就是对数据进行接收,然后将数据进行简单的时间区分,然后根据指定的时间和条件录入到集群中指定的目录下。例如,时间目录、数据来源目录以及地域目录等等。在这个部分实际上没有什么特别的描述,主要就是接收数据的形式方面,采用了流模式,提升传输的速度。对于一些延迟或是传输失败的数据采用文件搬运的模式。数据接收到本地之后采用Hadoop的API将数据录入到集群中。
二、Job管理端
对于这个部分,主要有以下功能点:
1、Job顺序控制。由于一个业务不可能是一个Job完成,可能需要多个Job来执行,先后存在一些依赖关系,所以通过对Job顺序的控制来完成一组业务。这个通过读取JobList的配置文件来确定先后顺序。
2、Job任务监控。同样,在这个部分主要是采用JobClient来实现。这里就不做细致的代码说明,查看Hadoop的API有详细的说明。如果确实需要代码可以发邮件给我。
3、实现Job的热拔插。由于业务分析的多变,所以需要对Job随时进行一些增删。例如一些Job可能需要新增加,而又有一些Job需要删除不执行。所以这个时候通过配置JobList清单就可以控制Job执行的顺序以及哪些Job执行哪些Job不执行。这样的操作不需要重启任何程序。
4、调度模式。每个业务可能需要多个Job,但是业务之间基本不存在依赖的关系,所以,这个时候,一个业务内的Job就需要实现FIFO模式,也就是顺序执行。但是对于业务之间,我们则需要考虑并发模式,也就是公平调度(公平调度模式需要配置,Hadoop默认是FIFO模式)。在集群支持公平调度模式的情况下,在Job管理端可以实现不同业务下Job的并发执行。

如上图:
1、所有的Business是可以并发的。但是同一个Business下的Job必须是顺序执行,因为存在依赖关系。
2、Job A、Job B、Job C是必须FIFO模式执行。而不同业务下的Job又是可以并发执行。
三、总结
1、分离出来的2种client有利于提升性能,同时具有良好的维护性。
2、Job的管理更加灵活。数据录入相对稳定。集群的计算影响减小。
3、当然,这里还没有提到如何将数据录入到RDBMS中,实际上,一个业务执行完成之后就会将结果数据录入到对应的RDBMS表中。
4、一些代码的编写基本上采用了Java,主要是考虑能更好的调用Hadoop的API。当然中间有些流程也采用了Shell脚本。
5、大体上设计内容如上,如果大家有疑问或是觉得我写的不对的地方欢迎大家发邮件交流。dajuezhao@gmail.com


发表评论

-
Hadoop的基准测试工具使用(部分转载)
2011-01-21 11:58 1563一、背景由于以前没有� ... -
分布式集群中的硬件选择
2011-01-21 11:58 1000一、背景最近2个月时间一直在一个阴暗的地下室的角落里工作,主要 ... -
Map/Reduce的内存使用设置
2011-01-21 11:57 1608一、背景今天采用10台� ... -
Hadoop开发常用的InputFormat和OutputFormat(转)
2011-01-21 11:55 1455Hadoop中的Map Reduce框架依 ... -
SecondaryNamenode应用摘记
2010-11-04 15:54 1028一、环境 Hadoop 0.20.2、JDK 1.6、 ... -
Zookeeper分布式安装手册
2010-10-27 09:41 1295一、安装准备1、下载zookeeper-3.3.1,地址:ht ... -
Hadoop分布式安装
2010-10-27 09:41 981一、安装准备1、下载hadoop 0.20.2,地址:http ... -
Map/Reduce使用杂记
2010-10-27 09:40 905一、硬件环境1、CPU:Intel(R) Core(TM)2 ... -
Hadoop中自定义计数器
2010-10-27 09:40 1495一、环境1、hadoop 0.20.22、操作系统Linux二 ... -
Map/Reduce中的Partiotioner使用
2010-10-27 09:39 882一、环境1、hadoop 0.20.22� ... -
Map/Reduce中的Combiner的使用
2010-10-27 09:38 1153一、作用1、combiner最基本是实现本地key的聚合,对m ... -
Hadoop中DBInputFormat和DBOutputFormat使用
2010-10-27 09:38 2400一、背景 为了方便MapReduce直接访问关系型数据 ... -
Hadoop的MultipleOutputFormat使用
2010-10-27 09:37 1648一、背景 Hadoop的MapReduce中多文件输出默 ... -
Map/Reduce中公平调度器配置
2010-10-27 09:37 1507一、背景一般来说,JOB� ... -
无法启动Datanode的问题
2010-10-27 09:37 2365一、背景早上由于误删namenode上的hadoop文件夹,在 ... -
Map/Reduce的GroupingComparator排序简述
2010-10-27 09:36 1307一、背景排序对于MR来说是个核心内容,如何做好排序十分的重要, ... -
Map/Reduce中分区和分组的问题
2010-10-27 09:35 1102一、为什么写分区和分组在排序中的作用是不一样的,今天早上看书, ... -
关于Map和Reduce最大的并发数设置
2010-10-27 09:34 1214一、环境1、hadoop 0.20.22、操作系统 Linux ... -
关于集群数据负载均衡
2010-10-27 09:33 854一、环境1、hadoop 0.20.22、操作系统 Linux ... -
Map/Reduce执行流程简述
2010-10-27 09:33 957一、背景最近总在弄MR的东西,所以写点关于这个方面的内容,总结 ...
相关推荐
8.6 删减DataNode 8.7 增加DataNode 8.8 管理NameNode 和SNN 8.9 恢复失效的NameNode 8.10 感知网络布局和机架的设计 8.11 多用户作业的调度 8.11.1 多个JobTracker 8.11.2 公平调度器 8.12 小结第三部分 ...
”大体来说,hadoop应用对系统的要求侧重计算、存储与网络性能的均衡,这一点则正好与英特尔X86平台不谋而合。英特尔至强7400/7500系列处理器已然为百度Hadoop集群奠定了坚实的硬件平台,今年英特尔发布的至强E5平台...
22412.2 挖掘中国移动的数据 22512.3 在StumbleUpon推荐最佳网站 22912.3.1 分布式StumbleUpon的开端 23012.3.2 HBase和StumbleUpon 23012.3.3 StumbleUpon上的更多Hadoop应用 23612.4 搭建面向企业查询的分析系统...
管理Hadoop8.1 为实际应用设置特定参数值8.2 系统体检8.3 权限设置8.4 配额管理8.5 启用回收站8.6 删减DataNode8.7 增加DataNode8.8 管理NameNode 和SNN8.9 恢复失效的NameNode8.10 感知网络布局和机架的设计8.11 多...
Hadoop实际应用经验的基础上,对比两者的优点和不足,加上自己的一些提炼和思考,设计了一套综合两者的系统,利用两者的优点, 补充两者的不足。具体的说,使用数据库水平分割的思想实现数据存储,使用MapReduce的...
不仅如此,它还可以作为毕设项目、课程设计、作业、甚至项目初期的立项演示。 【人工智能的深度探索】 人工智能——模拟人类智能的技术和理论,使其在计算机上展现出类似人类的思考、判断、决策、学习和交流能力。...
云应用集成的N种成功模式(Richard).pdf 人人网开放平台验证与授权方面实践.pdf 使用Chef和Cucumber进行行为(测试)驱动基础设施开发(Sai).pdf 利用同步数据复制最大化数据库的使用效率(Schooner).pdf 又拍网...
淘宝Fourinone(中文名字“四不像”)是一个四合一分布式计算框架,在写这个框架之前,我对分布式计算进行了长时间的思考,也看了老外写的其他开源框架,当我们把复杂的hadoop当作一门学科学习时,似乎忘记了我们想...
当然,处理分析这些海量数据目前可以借鉴的方案有很多:首先,在分布式计算方面有Hadoop里面的MapReduce并行计算框架,它主要针对的是离线的数据挖掘分析。此外还有针对实时在线流式数据处理方面的,同样也是分布式...
│ ├─主线2:大数据平台架构设计与应用 │ │ 14:20 - 15:10 钱津津_苏宁智慧零售之电商大数据实践.pdf │ │ 16:20 - 17:10 王晓鹏_品友大数据分析平台演进.pdf │ │ 17:10 - 18:00 李亚坤_Hadoop YARN在...
主流开源NoSQL及分布式存储的应用与思考.pdf 腾讯在线交易平台统一数据层高一致性解决方案.pdf NoSQL一致性实践:我对CAP的一点认识.pdf MongoDB at Qihoo 360.pdf MySQL Cluster实战初探 .pdf SAP HANA深度剖析.pdf...
主流开源NoSQL及分布式存储的应用与思考.pdf 腾讯在线交易平台统一数据层高一致性解决方案.pdf NoSQL一致性实践:我对CAP的一点认识.pdf MongoDB at Qihoo 360.pdf MySQL Cluster实战初探 .pdf SAP HANA深度剖析.pdf...
主流开源NoSQL及分布式存储的应用与思考.pdf 腾讯在线交易平台统一数据层高一致性解决方案.pdf NoSQL一致性实践:我对CAP的一点认识.pdf MongoDB at Qihoo 360.pdf MySQL Cluster实战初探 .pdf SAP HANA深度剖析.pdf...
在平台的设计和实施中要考虑到 与其他应用系统的整合,开发出多个类型的接口,能够 灵活接入其他系统、拓展服务类型。 医院大数据分析平台的总体框架 平台应适应于大数据处理要求,能支持PB级数据 大数提存储 数据...